


就在刚刚,谷歌向最强开源大模型的宝座发起进攻!
智东西2月22日凌晨报道,昨日晚间,谷歌毫无预兆地发布了开源模型Gemma,直接狙击Llama 2,继通过Gemini拳打OpenAI后,试图用Gemma脚踢Meta。

谷歌发布Gemma(图源:谷歌)
不同于Gemini的“全家桶”路线,Gemma主打轻量级、高性能,有20亿、70亿两种参数规模,能在笔记本电脑、台式机、物联网设备、移动设备和云端等不同平台运行。
性能方面,Gemma在18个基准测评中平均成绩击败目前的主流开源模型Llama 2和Mistral,特别是在数学、代码能力上表现突出,还直接登顶Hugging Face开源大模型排行榜。
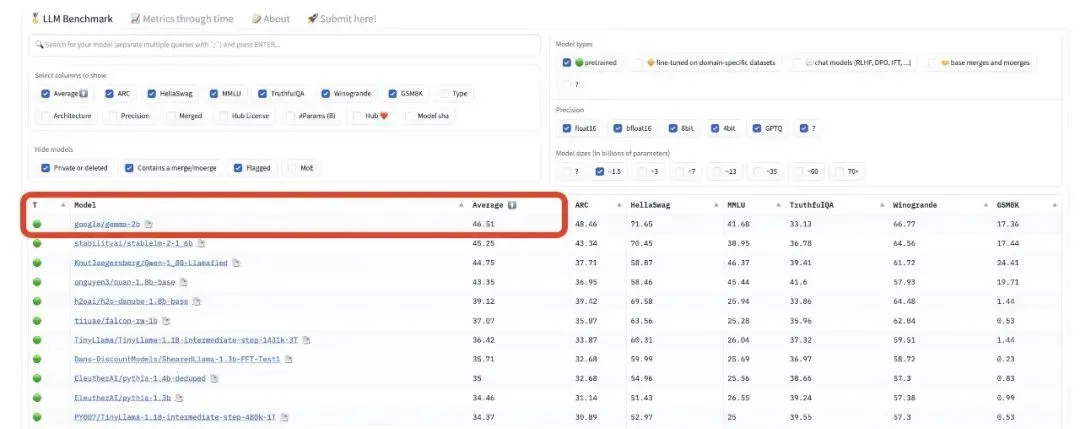
Gemma登顶Hugging Face开源大模型排行榜(图源:X)
谷歌同步放出了技术报告,通过深度解读,智东西注意到除了模型性能优异外,Gemma的分词器词表大小达到256k,这意味着它更容易扩展至其他语言。
谷歌还强调Gemma基于自家TPUv5e芯片训练,Gemma 7B使用了4096个TPUv5e,Gemma 2B使用了512个TPUv5e,秀出挑战英伟达GPU统治地位的“肌肉”。
短短12天,谷歌连续放出三个大招,先是9日宣布其最强大模型Gemini Ultra免费用,又在16日放出大模型“核弹”Gemini 1.5,再是21日突然放出开源模型Gemma,动作之密集、行动之迅速,似乎在向抢了自己风头的OpenAI宣战。
Gemma具体强在哪儿?它在哪些方面打赢了Llama 2?其技术原理和训练过程有哪些亮点?让我们从技术报告中寻找答案。
Gemma官网地址:
https://ai.google.dev/gemma
Gemma开源地址:
https://www.kaggle.com/models/google/gemma/code/
01.
采用Gemini相同架构
轻量级笔记本也能跑
据介绍,Gemma模型的研发是受到Gemini的启发,它的名字来源于意大利语“宝石”,是由谷歌DeepMind和其他团队共同合作开发。
Gemma采用了与Gemini相同的技术和基础架构,基于英伟达GPU和谷歌云TPU等硬件平台进行优化,有20亿、70亿两种参数规模,每个规模又分预训练和指令微调两个版本。
性能方面,谷歌称Gemma在MMLU、BBH、HumanEval等八项基准测试集上大幅超过Llama 2。
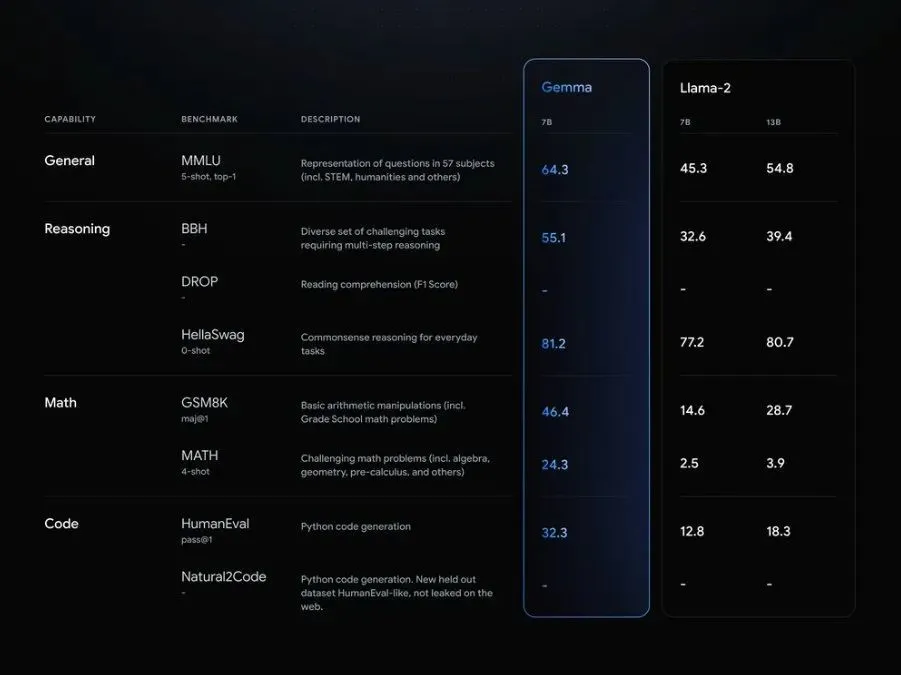
Gemma在基准测试上与Llama 2的跑分对比(图源:谷歌)
在发布权重的同时,谷歌还推出Responsible Generative AI Toolkit等一系列工具,为使用Gemma创建更安全的AI应用程序提供指导。此外,谷歌通过原生Keras 3.0为JAX、PyTorch和TensorFlow等主要框架提供推理和监督微调(SFT)的工具链。
谷歌强调Gemma在设计时将其AI原则放在首位,通过大量微调和人类反馈强化学习(RLHF)使指令微调模型与负责任的行为对齐,还通过手工红队测试、自动对抗性测试等对模型进行评估。
此外,谷歌与英伟达宣布合作,利用英伟达TensorRT-LLM对Gemma进行优化。英伟达上周刚发布的聊天机器人Chat with RTX也将很快增加对Gemma的支持。
即日起,Gemma在全球范围内开放使用,用户可以在Kaggle、Hugging Face等平台上进行下载和试用,它可以直接在笔记本电脑或台式机上运行。
发布才几个小时,已有不少用户分享了试用体验。社交平台X用户@indigo11称其“速度飞快”,“输出很稳定”。

X用户@indigo11分享Gemma试用体验(图源:X)
还有用户尝试了其他语种,称Gemma对日语的支持很流畅。
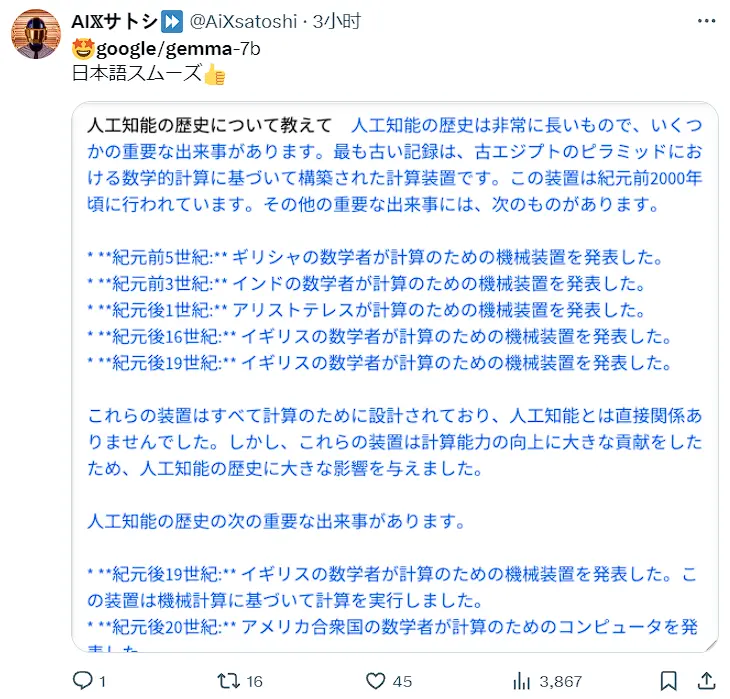
X用户@AiXsatoshi分享Gemma在日语上的试用体验(图源:X)
02.
数学、代码能力碾压Llama 2
采用自家TPUv5e训练
与Gemini发布时一样,谷歌此次也同步公开了Gemma的技术报告。

Gemma技术报告(图源:谷歌)
报告称,Gemma 2B和7B模型分别在2T和6T的tokens上进行训练,数据主要来自网络文档、数学和代码的英语数据。不同于Gemini,这些模型不是多模态的,也没有针对多语言任务进行训练。
谷歌使用Gemini的SentencePiece分词器的一个子集以保证兼容性。它分割数字但不去除额外的空格,并且对未知标记依赖于字节级编码,词表大小为256k个tokens,这可能意味着它更容易扩展到其他语言。

开发者称256k分词器值得注意(图源:X)
两个规模中,70亿参数的Gemma 7B适用于GPU、TPU上的高效部署和开发,20亿参数的Gemma 2B则适用于CPU。
Gemma基于谷歌的开源模型和生态构建,包括Word2Vec、BERT、T5、T5X等,其模型架构基于Transformer,主要核心参数如下表。
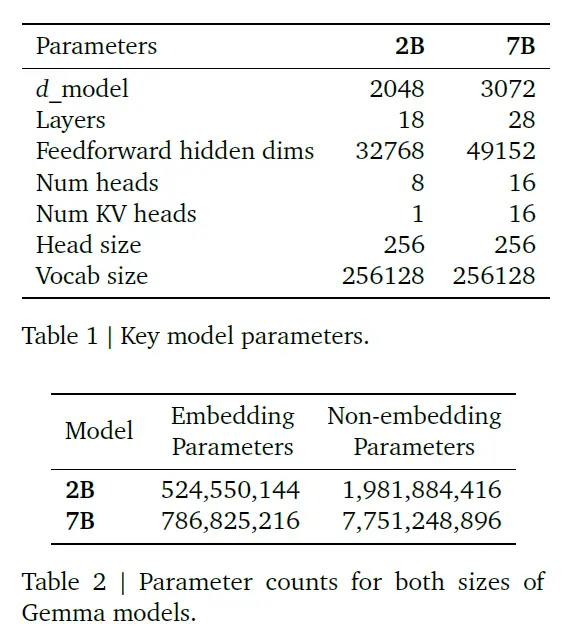
Gemma模型主要参数(图源:谷歌)
在基准测评中,Gemma直接对标目前先进的开源模型Llama 2和Mistral,其中Gemma 7B在18个基准上取得11个优胜,并以平均分56.4高于同级别模型。
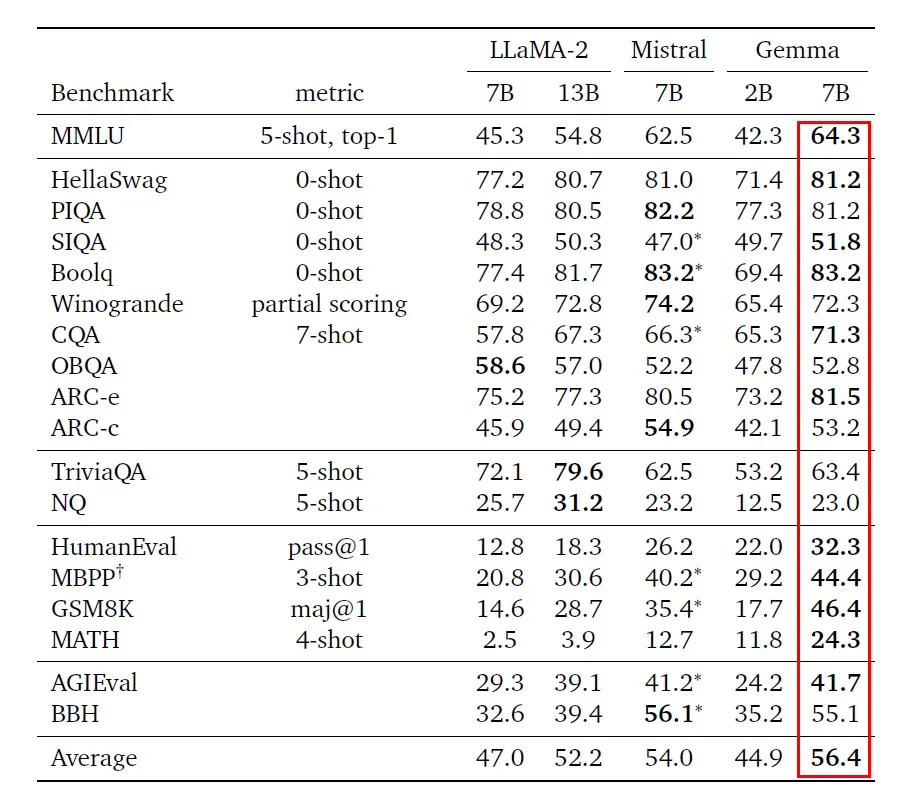
Gemma与Llama 2、Mistral基准测评分数对比(图源:谷歌)
从具体能力上看,Gemma 7B在问答、推理、数学/科学、代码等方面的标准学术基准测试平均分数都高于同规模的Llama 2和Mistral模型。
此外,其推理、数学/科学、代码能力还高于规模更大的Llama 2 13B。
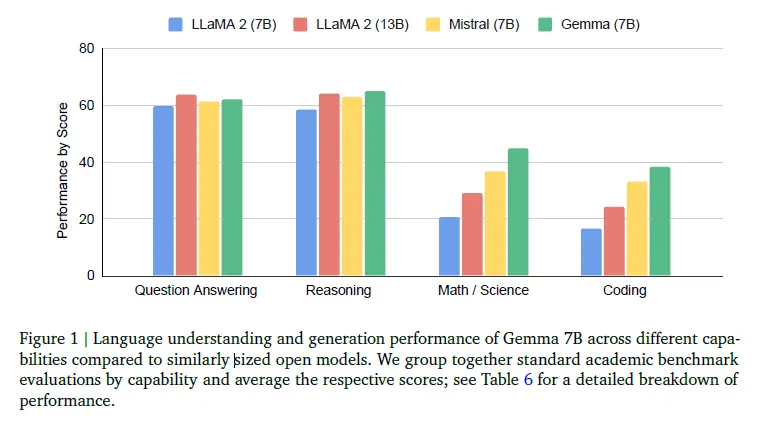
Gemma与Llama 2、Mistral各能力对比(图源:谷歌)
报告还详细介绍了Gemma训练采用的硬件:使用部署在256个芯片组成的Pod中的TPUv5e训练,这些Pod配置成一个16*16芯片的2D环形网络。
其中,Gemma 7B模型跨16个Pod进行训练,共使用了4096个TPUv5e;Gemma 2B模型跨越2个Pod进行训练,共使用了512个TPUv5e。
在一个Pod内部,谷歌为Gemma 7B使用了16路模型分片和16路数据复制,Gemma 2B则使用256路数据复制。优化器状态进一步通过类似于ZeRO-3的技术进行分片。
技术报告地址:
https://goo.gle/GemmaReport
03.
被OpenAI逼急了
谷歌一月连放三大招
2024开年,OpenAI发布的Sora文生视频模型爆火,一举抢走了谷歌最新力作Gemini 1.5 Pro大模型的风头。
但谷歌并没有就此打住,而是乘胜追击放出一个月里的第三个大招,这三个大招分别是:
2月9日大年三十,谷歌宣布其最强大模型Gemini Ultra免费用,Gemini Ultra于2023年12月发布时在MMLU(大规模多任务语言理解)测评上超过人类专家,在32个多模态基准中取得30个SOTA(当前最优效果),几乎全方位超越GPT-4,向OpenAI发起强势一击。(《谷歌大年三十整大活!最强大模型Gemini Ultra免费用,狙击GPT-4》)
2月16日大年初七,谷歌放出其大模型核弹——Gemini 1.5,并将上下文窗口长度扩展到100万个tokens。Gemini 1.5 Pro可一次处理1小时的视频、11小时的音频、超过3万行代码或超过70万字的代码库,向OpenAI还没发布的GPT-5发起挑战。 (《谷歌Gemini 1.5模型来了!突破100万个tokens,能处理1小时视频【附58页技术报告】》)
2月21日正月十二,谷歌在被“抢头条”后,一举将采用创建Gemini相同研究和技术的Gemma开源,一方面狙击Llama 2等开源模型,登上开源大模型铁王座,同时为嗷嗷待哺的生成式AI的应用开发者带来福音,更是为闭源的代表OpenAI狠狠地上了一课。
自2022年12月ChatGPT发布以来,AI领域扛把子谷歌就陷入被OpenAI压着打的境地,“复仇”心切。
在GPT-3大模型问世前,DeepMind的风头更胜一筹,坐拥AlphaGo、AlphaGo Zero、MuZero、AlphaFold等一系列打败人类的明星AI模型。随着生成式AI风口渐盛,谷歌DeepMind却开始显得力不从心,ChatGPT引发谷歌AI人才大军流向OpenAI,OpenAI却由此扶摇直上。
2023年3月,谷歌促成谷歌大脑和DeepMind冰释前嫌,合并对抗OpenAI,被业内称为“谷歌复仇联盟”。然而,直到年底的12月7日,谷歌最强大模型Gemini才姗姗来迟,尽管效果惊艳却令市场有些意兴阑珊。2024年1月31日,谷歌最新财报显示其收入亮眼,却因AI方面进展不及预期市值一夜蒸发超1000亿美元。
然而,2024年2月一来到,谷歌的状态来了个180度大转弯,攒了一年的大招接二连三地释放,试图用强大的Gemini大模型矩阵证明,其是被严重低估的。
值得一提的是,谷歌还有另一张王牌是自研芯片,有望成为其与OpenAI抗衡的有力底牌。2023年8月,谷歌云发布最新云端AI芯片TPU v5e,TPU被视作全球AI芯片霸主英伟达GPU的劲敌。
据半导体研究和咨询公司SemiAnalysis的分析师曝料,谷歌拥有的算力资源比OpenAI、Meta、亚马逊、甲骨文和CoreWeave加起来还要多,其下一代大模型Gemini已经开始在新的TPUv5 Pod上进行训练,算力达到GPT-4的5倍,基于其目前的基础设施建设情况,到明年年底可能达到20倍。
04.
结语:谷歌再放大招
拳打OpenAI,脚踢Meta
从2023年12月发布Gemini多模态大模型,到2024年2月连放Gemini Ultra免费版、Gimini 1.5、Gemini技术开源三个大招,谷歌的大模型矩阵逐渐清晰,从闭源和开源两大路线对OpenAI打响复仇战,也向推出开源模型Llama 2的Meta宣战。
当下,OpenAI的文生视频大模型Sora风头正盛。实际上,谷歌已于2023年12月推出了用于零样本视频生成的大型语言模型VideoPoet,可在单个大模型中无缝集成了多种视频生成功能。谷歌在文生视频领域的储备想必也深,可以预测后续和OpenAI有得一打,而压力也就此给到了国内的AI企业。
转载请注明出处华人站华人新闻,华人中文网 » 谷歌向最强开源大模型的宝座发起进攻!