

8 月 7 日消息,Meta 公司于 8 月 5 日发布博文,表示为了满足大规模分布式 AI 训练对网络的需求,构建了基于 RoCEv2 协议的大规模 AI 网络。
RoCEv2 的全称是 RDMA Over Converged Ethernet version 2,是一种节点间通信传输方式,用于大部分人工智能容量。
Meta 公司已成功扩展了 RoCE 网络,从原型发展到部署了众多集群,每个集群可容纳数千个 GPU。
这些 RoCE 集群支持广泛的生产型分布式 GPU 训练工作,包括排名、内容推荐、内容理解、自然语言处理和 GenAI 模型训练等工作负载。
Meta 公司为分布式 AI 训练专门建立了一个专用的后端网络,能够独立于数据中心网络的其他部分进行发展、运行和扩展。
训练集群依赖于两个独立的网络:前端(FE)网络用于数据摄取、检查点和日志记录等任务,后端(BE)网络用于训练,如下图所示:
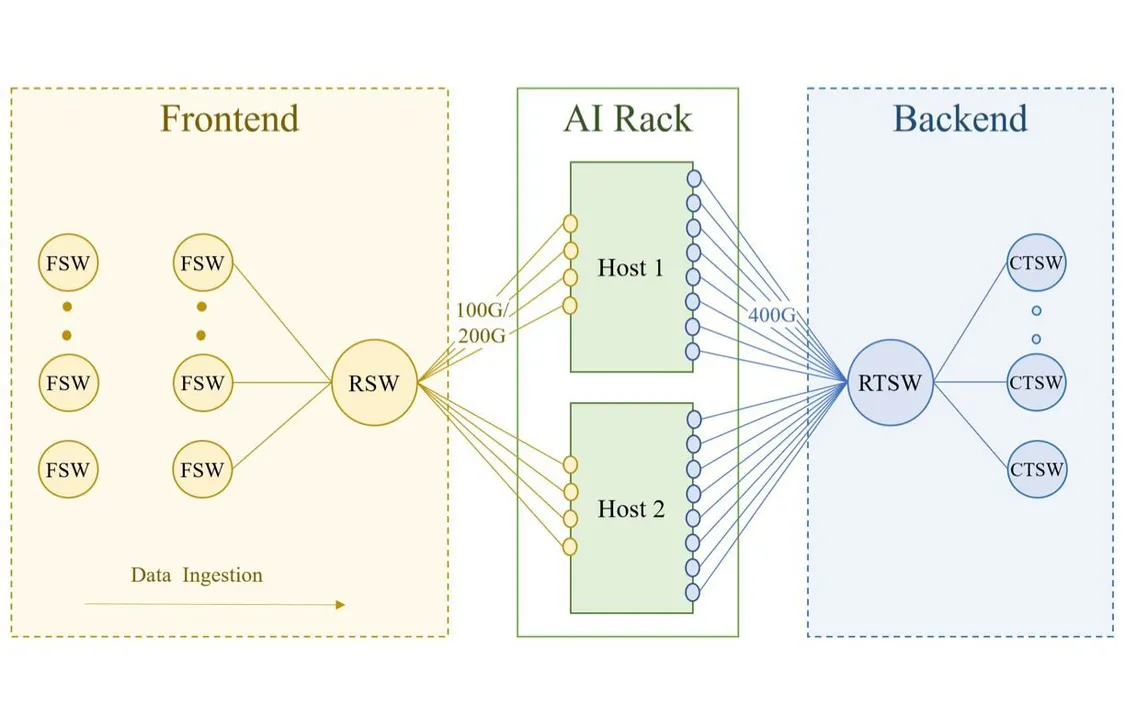
训练机架连接到数据中心网络的 FE 和 BE。FE 的网络层次包括机架交换机 (RSW)、结构交换机(FSW)等,其中包含存储仓库,为 GPU 提供训练工作负载所需的输入数据。

后端结构是一个专门的结构,它以无阻塞的架构连接所有 RDMA 网卡,无论它们的物理位置如何,在集群中的任意两个 GPU 之间提供高带宽、低延迟和无损传输。
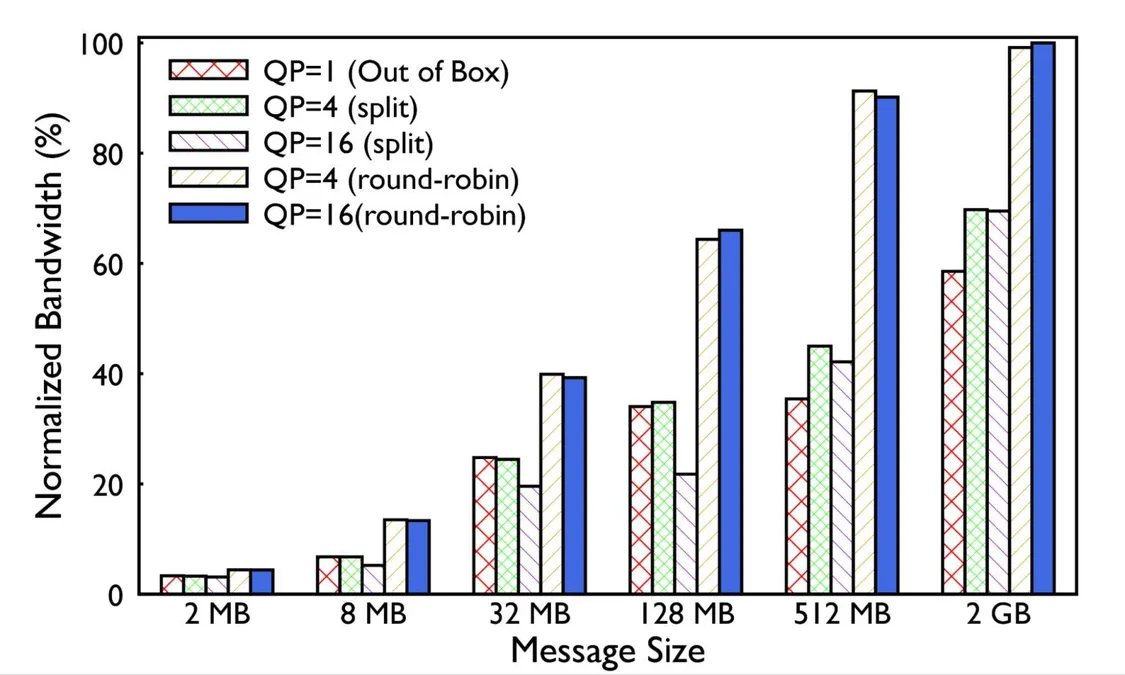

为了应对 LLM 模型训练对 GPU 规模的需求,Meta 设计了聚合训练交换机(ATSW)层,将多个 AI 区域互连起来。此外,Meta 还优化路由、拥塞控制等方面,以提升网络性能。
转载请注明出处华人站华人新闻,华人中文网 » Meta构建分布式RoCEv2网络:探索串联数万片GPU,训练千亿参数级AI模型