


字节跳动扔出一颗石子,在大模型行业炸出了一片水花。
15日,字节跳动推出豆包大模型,仅需0.8厘就能处理1500多个汉字。阿里、腾讯、百度紧跟而上掀起了一场大模型价格战。一夜之间,大模型从以美元计价变成了以厘计价。
历史总是出奇相似。经历“百团大战”“打车大战”后,大模型的价格战能否走出“跑马圈地”的怪圈?
到底有多便宜
这一场价格战从5月初开始。
DeepSeek在6日宣布,旗下大模型DeepSeek-V2降价至每百万Tokens(处理文本最小单位)输入价格为1元、输出价格为2元,开发者还将获得500万Tokens的免费额度。
这个价格有多低?用OpenAI的主力大模型GPT-4 Turbo作比对就很明显——每百万Tokens的输入和输出价格分别为72元和217元。
但是两者近百倍的价差,并未引发市场太大的反响,直至字节跳动的加入。
5月15日,字节跳动发布豆包大模型,宣布主力大模型pro-32k定价为0.8元/百万Tokens,号称比行业便宜99.3%,比DeepSeek-V2还低不少。
 火山引擎总裁谭待公布豆包大模型定价。
火山引擎总裁谭待公布豆包大模型定价。
21日,阿里云宣布通义千问主力模型Qwen-Long,API(编程接口)输入价格从20元/百万Tokens降至0.5元/百万tokens,直降97%。这意味着,1元钱可以买200万Tokens,相当于5本《新华字典》的文字量。
紧接着,百度随即宣布文心大模型的两款主力模型 ENIRE Speed、ENIRE Lite全面免费。这两款大模型均支持客户向大模型进行8K—128K内容量的提问和回答。
腾讯云旗下混元大模型跟着降价,其中混元—lite模型免费,混元—standard—256k输入价格下调87.5%至15元/百万Tokens。
需要提醒的是,各个平台大模型的参数不一样,最终价格也不尽相同,但价格降幅均在50%以上,是实打实的“打骨折”。相比之下,国内外厂商Gemini1.5 Pro、Claude 3 Sonnet及Ernie-4.0每百万Tokens输入价格分别为25元、22元及120元。
国产大模型的价格战到底有多卷?火山引擎总裁谭待算了一笔账:以主力模型32k(约3.2万个参数)为例,看看1元钱能买到多少Token?此前,1元钱可以从GPT买到2400个Tokens,国内大模型能得到8000多个Tokens,如果用开源Llama搭建自己的大模型,1元钱可获得3万个Tokens。
在字节跳动的“鲶鱼效应”下,如今只要花一元钱,就能获得百万级别Tokens,相当于“读”完5本《新华字典》或3本《三国演义》。
为何要打价格战
AI大模型是出了名的烧钱行业,在全球竞争的当下,算力、研发、运维等成本几乎都用美元计算,钱还没赚到,为何先打起了价格战?
目前看来,互联网“赔本赚吆喝”的逻辑依然贯穿始终。
一位大模型研发技术人员告诉记者,动辄百万级别Tokens的计费模式虽然没错,但更多的是营销噱头而非实际能力,以大模型应用落地来看,《新华字典》级别的文本量不如对多模态的深度理解。“按照几毛几分的收费,大模型可能是亏钱的,但好在能够吸引更多开发者和客户,用短线亏损换取用户基数,长期来看也算是一种商业策略。”他说道。
 阿里云宣布通义千问大模型降价。
阿里云宣布通义千问大模型降价。
降价能否带来用户增长?阿里云在上半年的实践证明是有效的。
3月1日开始,阿里云开启新一轮的降价政策,核心产品平均降幅20%,最高幅度达55%。通过此次大规模降价,阿里云表示希望更多企业和开发者用上公共云服务,加速云计算在中国各行各业的普及和发展。
最近阿里财报显示,阿里云季度营收同比增长3%至255.95亿元,核心公共云产品收入实现两位数增长,AI相关收入实现三位数增长。
不过,公共云的成功能否复制在大模型上,阿里、字节、腾讯等巨头“大厂”决定放手一搏,但大模型的“中小厂”却有不同的看法。
比如李开复创立的零一万物最新发布的Yi—Large模型每百万Tokens定价20元,与国外主流大模型类似。虽然他认可大模型的推理成本在未来将不断降低,但并不打算现在跟风价格战,“ofo式疯狂降价”是一种双输的策略。在“做一单赔一单”的市场环境下,李开复坦言将服务国外市场的B端客户。
百川智能CEO王小川也有类似观点,他也建议创业公司不要掺和价格战,大模型创业并不适合网约车和百团大战时期“烧钱补贴”的策略,低价不应该成为大模型的唯一竞争力。
今后如何收费
从卷长文本到卷多模态再到卷价格,短短一年内,大模型在国内火速“进化”,从基础技术到落地应用,国内大模型迎来了商业化的序幕。
《中国大模型中标项目监测报告》显示,今年前四个月,大模型相关中标金额已超过去年全年7成以上,涉及政务、金融、能源等多行业,由此可见,传统行业正加速拥抱大模型。科技巨头的数据也能印证这一点:百度文心大模型每天处理文本量达到2500亿Tokens,而字节跳动每天处理1200亿Tokens。
目前,大模型在B端的商业化落地主要有API调用和私有化部署两种渠道,千亿级的数据处理能力,显然不是每个公司都能承受的,公有云+API成了越来越多企业的选择。
“去年很多客户说买一两百台GPU服务器,自行搭建计算网络集群研发大模型,而今年不少公司已经放弃这一计划。”阿里云公共云事业部总裁刘伟光解释说,构建一个大规模集群需要GPU显卡采购、软件部署、网络费用、电费、人力成本以及不断投入的试错成本。但是在公共云上的调用价格也远远低于私有化部署。
他以使用Qwen-72B开源模型、每月1亿Tokens用量为例,在公有云上直接调用API每月仅需600元,而私有化部署的成本平均每月超1万元,“大模型的规模越大,云上的优势就越明显”。
C端商业化又是另一条路径。
“B端降价,C端收费,国内大模型以后可能要走上OpenAI的老路。”上述研发人员告诉记者,大模型在B端低价吸引开发者,当技术生态逐步完善后,C端应用也就到了“收割”期。以OpenAI为例,面向C端用户推出ChatGPT Plus,会员需要支付每月20美元订阅费,面对B端开发者提供API调用服务。去年OpenAI的年度经常性收入据报道已达到16亿美元。
今年推出的GPT-4o与早期GPT3.5类似,免费的限次数使用,付费的无限制使用。百度的文心一言大模型亦是如此:文心3.5版本可免费使用,但是升级成文心4.0版本则需要开通每月至少49.9元的会员。
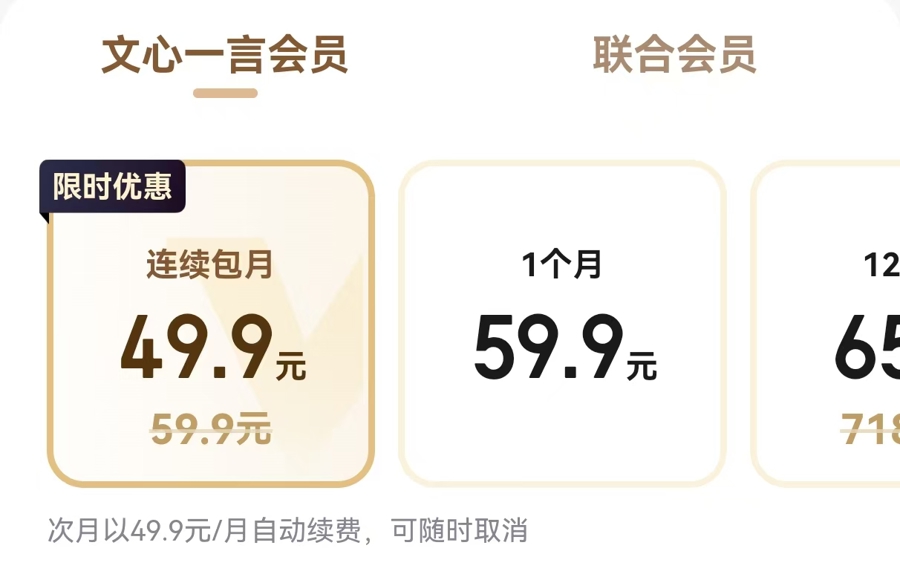 文心4.0版本需要开通每月至少49.9元的会员。
文心4.0版本需要开通每月至少49.9元的会员。
国内的Kimi近期推出的打赏功能,也是C端收费的探索之一。Kimi在高峰算力不足时,可提供打赏获得优先权,价格分别为5.2元、9.99元、28.8元、49.9元、99元和399元,打赏后分别可获得4天、8天、23天、40天、93天和365天的高峰期优先使用权。
转载请注明出处华人站华人新闻,华人中文网 » 一夜之间,大模型从以美元计价变成了以厘计价